
|

|

|

|

|

|

|

|
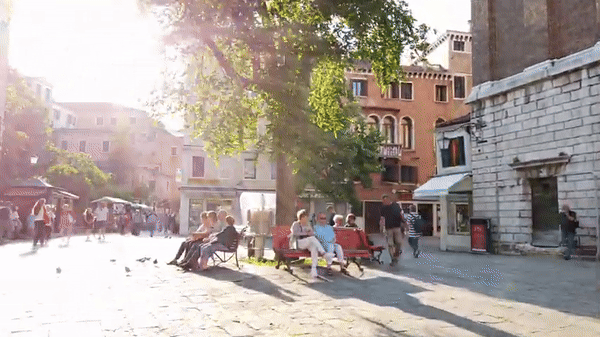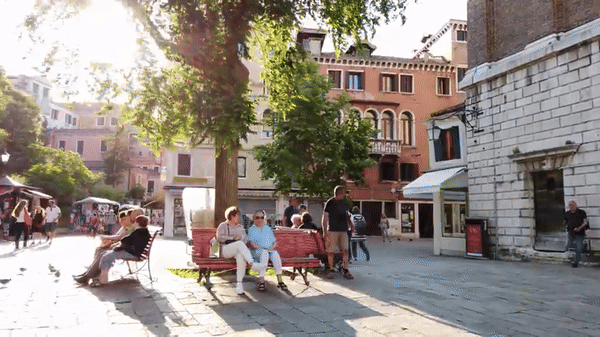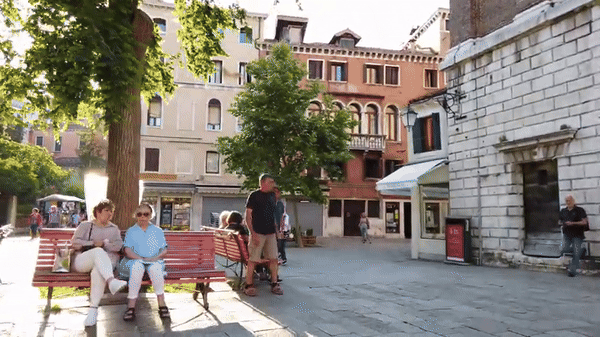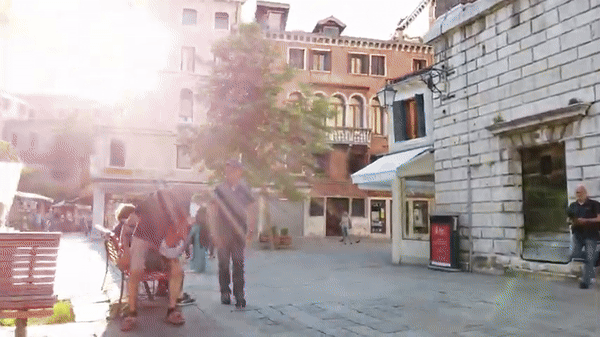
|
|
|
|
|
|
|
|
|
|
|
|
|
Self-supervised learning has unlocked the potential of scaling up pretraining to billions of images, since annotation is unnecessary. But are we making the best use of data? How more economical can we be? In this work, we attempt to answer this question by making two contributions. First, we investigate first-person videos and introduce a "Walking Tours" dataset. These videos are high-resolution, hours-long, captured in a single uninterrupted take, depicting a large number of objects and actions with natural scene transitions. They are unlabeled and uncurated, thus realistic for self-supervision and comparable with human learning. Second, we introduce a novel self-supervised image pretraining method tailored for learning from continuous videos. Existing methods typically adapt image-based pretraining approaches to incorporate more frames. Instead, we advocate a "tracking to learn to recognize" approach. Our method called DoRA leads to attention maps that DiscOver and tRAck objects over time in an end-to-end manner, using transformer cross-attention. We derive multiple views from the tracks and use them in a classical self-supervised distillation loss. Using our novel approach, a single Walking Tours video remarkably becomes a strong competitor to ImageNet for several image and video downstream tasks. |
|
|
|
|
|
|
|
|
|
|
|
|
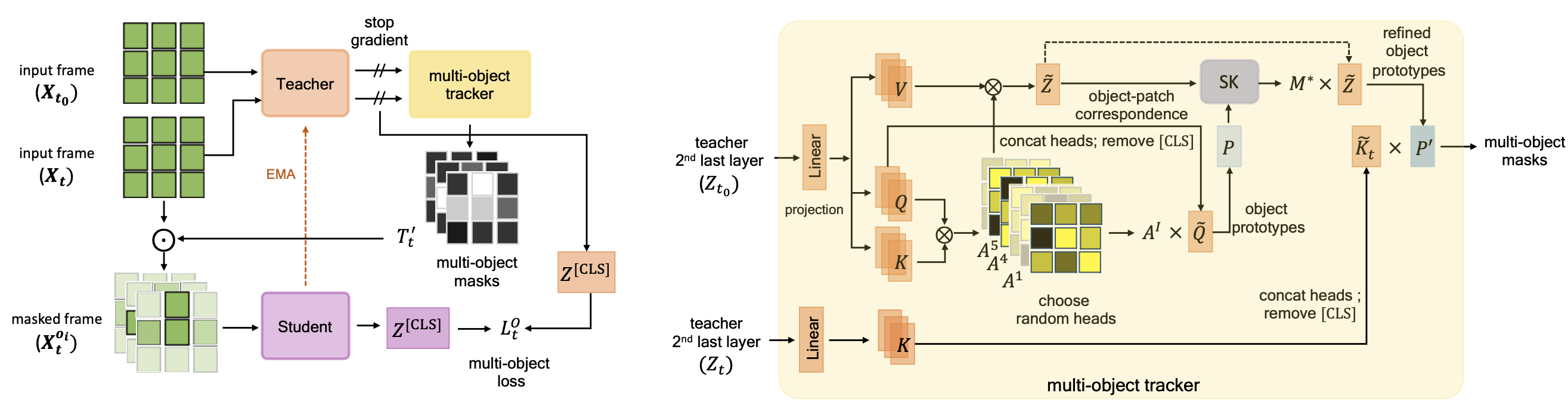 |
| We introduce DoRA, based on multi-object Discovery and Tracking. As shown in figure above, it leverages the attention from the [CLS] token of distinct heads in a vision transformer to identify and consistently track multiple objects within a given frame across temporal sequences. On these, a teacher-student distillation loss is then applied. Importantly, we do not use any off-the-shelf object tracker or optical flow network. This keeps our pipeline simple and does not require any additional data or training. It also ensures that the learned representation is robust. |
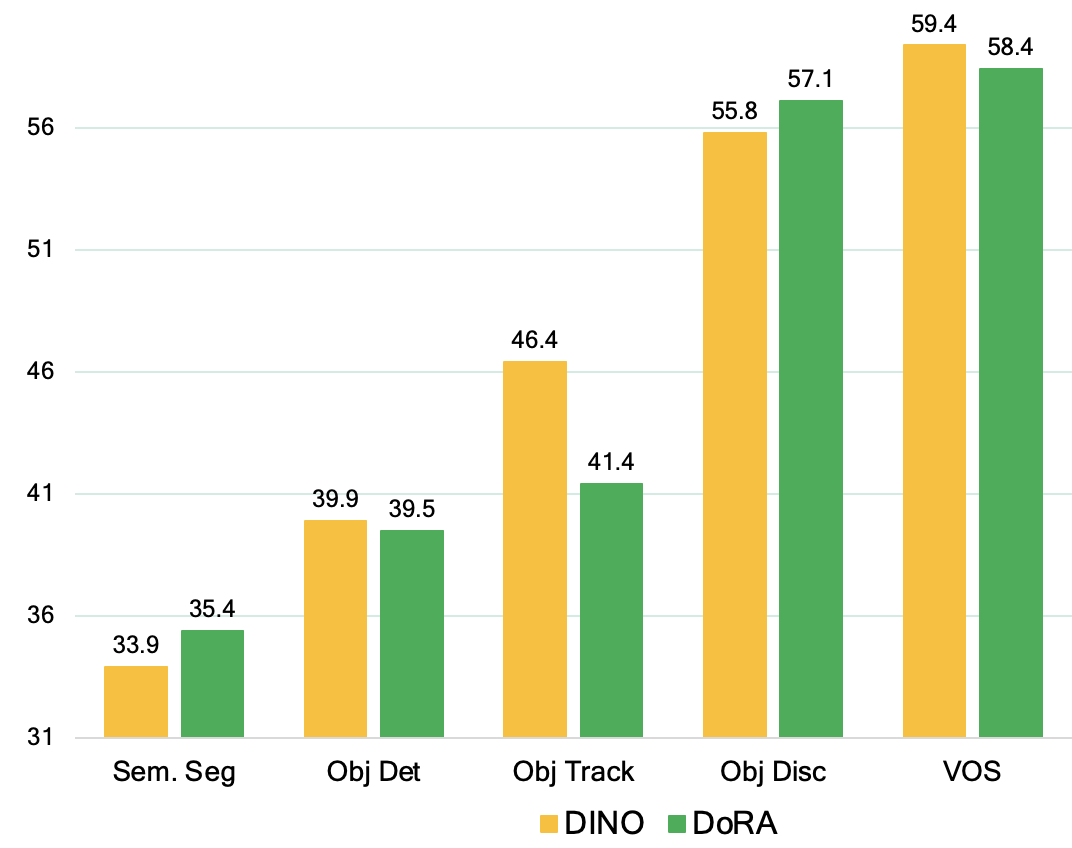
Using just 1 video, DoRA outperforms DINO pretrained on ImageNet-1K on obj discovery and semantic segmentation. |
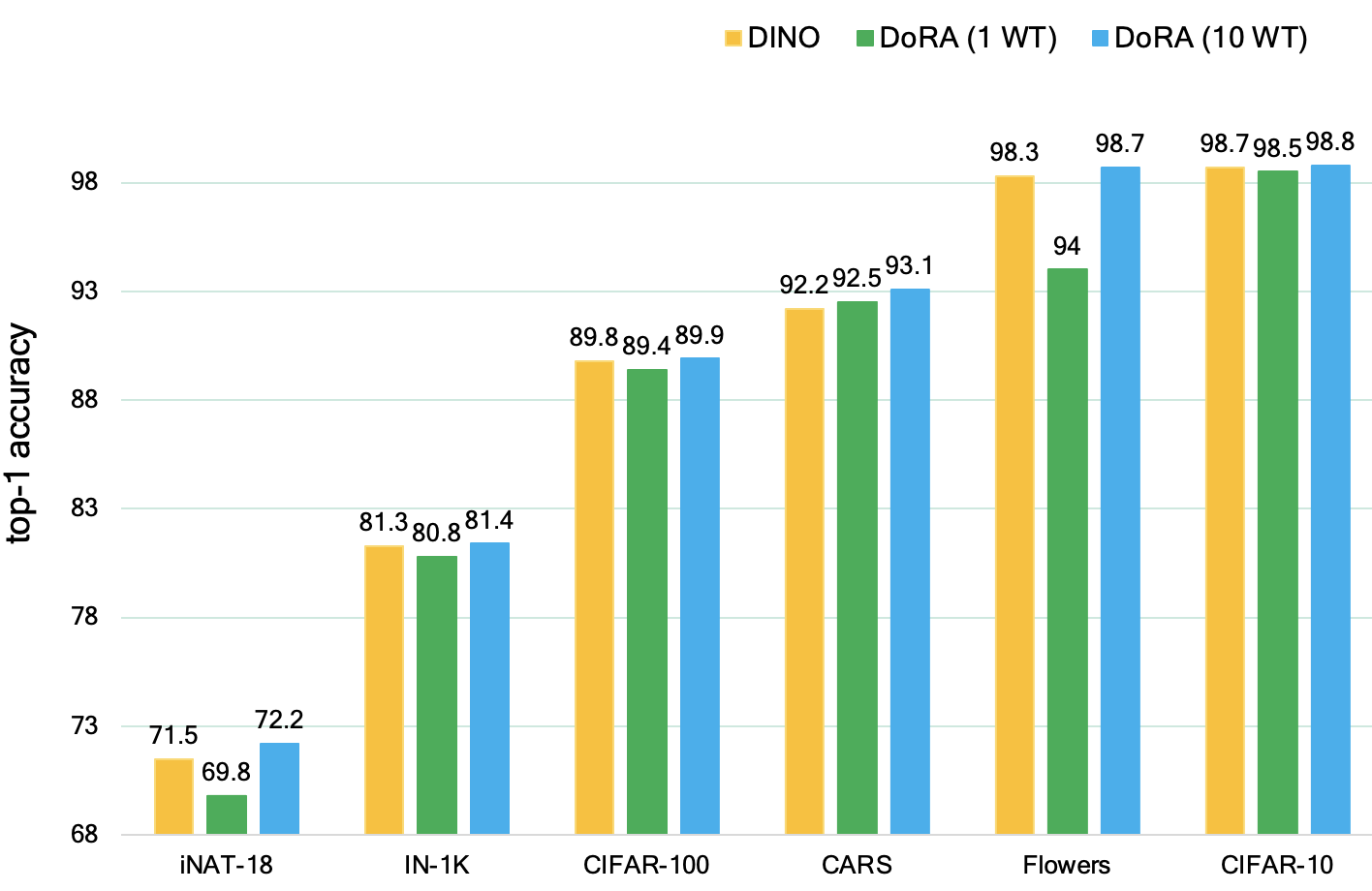
Finetuning on different image-based datasets. DoRA pretrained on 10 WTour videos outperforms DINO pretrained on ImageNet-1K |
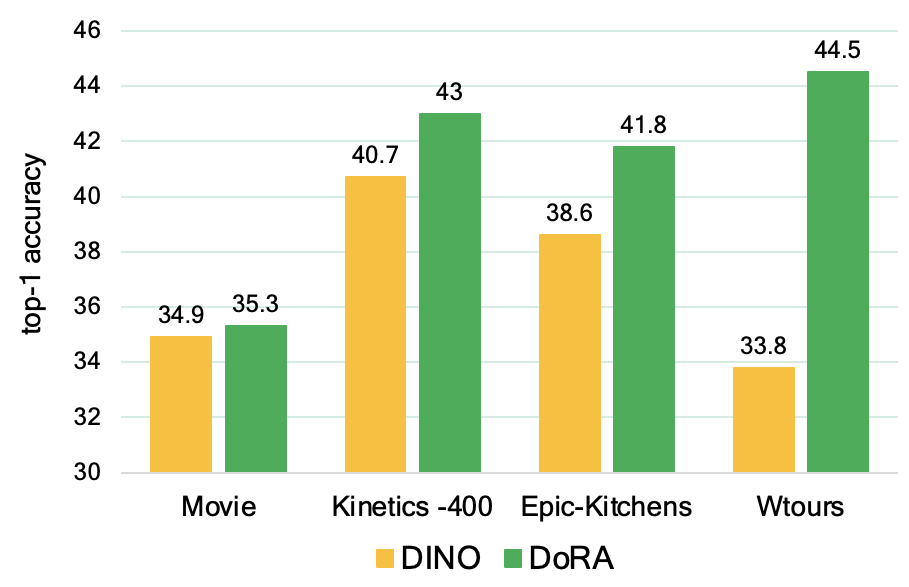
Linear Probing on different video pretraining datasets e.g. Epic-Kitchens, Kinetics-400 and Movies (randomly chosen from romantic genre) |

|

|

|

|
 |
S. Venkataramanan, M. Rizve, J. Carreira, Y.M. Asano, Y. Avrithis Is ImageNet worth 1 video? Learning strong image encoders from 1 long unlabelled video In International Conference on Learning Representations, 2024. (hosted on ArXiv) |